发布时间:2025-08-08 11:14:06
OpenAI带着GPT-5强势回归,再次革新人工智能体验!GPT-5智能性能远超过往模型,在编码、数学等多领域表现卓越。写作时,它像灵感爆棚的诗人,产出的文字兼具文采与深度。此外,其编程能力出色,还能为健康问题答疑解惑。全新GPT-5,为你开启智能新时代。

OpenAI官方正式推出了备受外界期待的、性能更强的新一代人工智能模型GPT-5。
OpenAI在新闻稿中写道,GPT-5的智能性能远超公司之前的所有模型,在编码、数学、写作、健康、视觉感知等领域均拥有卓越的性能。
声明补充称,GPT-5是一个统一的系统,能够识别何时快速响应,何时需要更长时间的思考以提供专家级的应答,不必由用户手动选择使用常规语言模型还是推理系统。
OpenAI表示,GPT-5将面向所有用户开放,Plus会员可获得更多使用量,Pro会员则可访问GPT-5 Pro版本——该版本具有扩展推理能力,可提供更全面、更准确的答案。
先前,OpenAI首席执行官萨姆·奥尔特曼(Sam Altman)称GPT-5是一次“重大升级”,“这还是第一次,真的像是在与某个领域的专家对话。”
ChatGPT团队负责人Nick Turley表示,新模型在响应速度、回答准确性以及减少“幻觉”方面都优于前代产品,“你跟它对话时,会感觉自然了不少。”
在8月7日的简报会上,奥尔特曼对GPT-5给予了极高评价,将GPT-5定位为通往AGI的重要里程碑。他表示:“在以往历史上任何时期,拥有像GPT-5这样的东西都是不可想象的。”
“这是第一次感觉就像在与任何领域的专家交谈。”Altman在简报会上甚至不惜用“踩”GPT-4抬高GPT-5。他说:“我尝试过用回GPT-4,但效果相当糟糕。”

GPT-5拥有编程、创意写作、健康领域三大优势
根据OpenAI介绍,作为OpenAI的“最强大模型”,GPT-5在三个关键领域实现了显著提升。
首先是编程能力。GPT-5是OpenAI迄今为止最强大的编码模型,在复杂的前端生成和大型代码库调试方面表现突出,能够仅凭一个提示就创建美观响应式的网站、应用程序App和游戏。早期测试者注意到其在间距、排版和留白等设计选择方面的改进。
在从GitHub获取现实世界编码任务的基准测试SWE-bench Verified中,GPT-5思考后首次尝试的准确率达74.9%,高于OpenAI推理模型o3的69.1%和GPT-4o的30.8%。
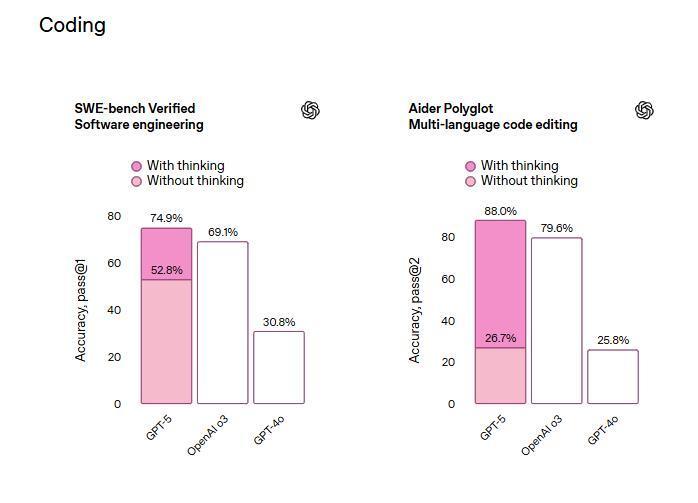
评论指出,这意味着,GPT-5的表现略胜于Anthropic周二推出的Claude Opus 4.1和谷歌DeepMind的Gemini 2.5 Pro,后两者在SWE-bench Verified测试的得分分别为74.5%和59.6%。
不过,在衡量数学、人文和自然科学领域模型表现的各学科专家级能力Humanity’s Last Exam测试中,带有扩展推理功能的GPT-5增强版本GPT-5 pro在使用工具的情况下得分42%。这略低于得分44.4%的xAI模型Grok 4 Heavy。

奥尔特曼称,GPT-5尤其擅长按需启动整个软件App,也就是所谓的“氛围编码”、即用AI根据自然语言提示生成功能代码,从而加快开发速度。
作为实例,OpenAI的研究者演示了,要求GPT-5创建一款网页App,帮助说英语的用户学习法语,且该App必须有一个引人入胜的主题,包含抽认卡、测验、经典的贪吃蛇游戏,以及追踪每日学习进度的方法。
研究者将相同的提示词提交到两个GPT-5 窗口中,几分钟后生成了两个不同的App。OpenAI的负责人称,这些App“存在一些缺陷”,但用户可以根据个人喜好再调整AI生成的软件,例如更改背景或添加更多标签页。
在创意写作方面,GPT-5能够处理结构复杂的写作任务,如无韵律的抑扬格五音步诗或自然流动的自由诗,犹如诗人。OpenAI的ChatGPT业务副总Nick Turley表示,GPT-5在创意任务上表现出“更好的品味”,响应更自然。

健康咨询是第三个重要提升领域。
GPT-5能更积极地标记潜在健康问题,帮助用户解析医疗结果,尽管OpenAI强调,ChatGPT不能替代医疗专业人员。
在名为HealthBench Hard Hallucinations的测试中,具备思考能力的GPT-5出现幻觉的错误信息率仅为1.6%。这远低于GPT-4o和o3模型,后两者的错误信息率分别为15.8%和12.9%。
OpenAI称,GPT-5相比此前的模型更可靠和实用,它能更准确地回答现实世界的疑问,出现幻觉的可能性显著降低。
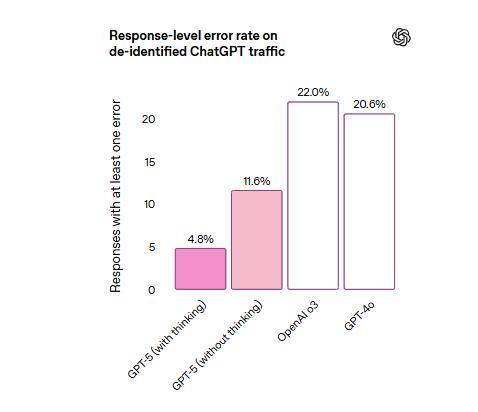
在对代表ChatGPT生产流量的匿名提示词启用网络搜索后,GPT-5响应中包含事实错误的可能性比GPT-4o低约45%;在思考后,GPT-5响应中包含事实错误的可能性比o3低约 80%。下图可见,GPT-5响应的错误信息率仅为4.8%,GPT-4o为20.6%,o3为22%。
OpenAI还表示,为GPT-5引入了一种新的安全训练形式,名为安全补全(safe completions)。它教模型在安全范围内尽可能给出最有帮助的答案。有时,这可能意味着部分回答用户的问题,或者只提供高水平的回答。
如果需要拒绝,经过训练的GPT-5会以透明的方式告知用户拒绝的原因,并提供安全的替代方案。
在受控的实验和OpenAI的生产模型中,OpenAI都发现这种安全补全的方法更加细致入微,能够更好地引导双重用途问题,增强对模糊意图的鲁棒性,并减少不必要的过度拒绝。
OpenAI的后训练负责人Michelle Pokrass表示:“GPT-5已经过训练,能够识别任务何时无法完成,避免猜测,并能更清晰地解释局限性,相比之前的模型,这减少了无根据的断言。”
OpenAI称,GPT-5在指令执行方面表现提升,其执行自定义指令的能力也得到了相应的提升。OpenAI将为所有ChatGPT用户推出四种预设性格的全新研究预览版。
初始的四种性格选项——愤世嫉俗者(Cynic)、机器人(Robot)、倾听者(Listener)和书呆子(Nerd)都是可选的,用户可在设置中随时调整,用以匹配ChatGPT和用户的沟通风格。
上述四种性格最初适用于文本聊天,之后将扩展到语音聊天,让用户无需编写自定义提示词即可设置ChatGPT的交互方式——无论是简洁专业的、周到支持的,还是略带讽刺的。
此外,微软在GPT-5发布当日即宣布,将其整合到广泛的产品线中。在企业级应用方面,Microsoft 365 Copilot将利用GPT-5更好地处理复杂问题、在长对话中保持专注并理解用户上下文。企业用户可通过推理功能处理电子邮件、文档和文件。
对于消费者,Microsoft Copilot的新智能模式将利用GPT-5帮助用户发现最佳解决方案。用户可通过copilot.microsoft.com或Windows、Mac、Android和iOS设备上的Copilot应用免费体验GPT-5。
开发者将通过GitHub Copilot和Visual Studio Code获得GPT-5支持,用于编写、测试和部署代码。Azure AI Foundry平台将提供所有GPT-5模型,配备AI驱动的模型路由器,根据每个任务的复杂性、性能需求和成本效率选择最优模型。

4月23日《阿尔比恩之主》抢测开启 领略上帝视角的战略模拟魅力
2由22cans工作室倾力打造的上帝视角战略模拟新作《阿尔比恩之主》,即将于4月23日开启抢先测试,期待与各位玩家见面!

4月30日《鸣潮》3.3更新来袭,全新要素提前揭秘
KURO GAMES旗下热门游戏《鸣潮》3.3版本更新“响彻于坠星之地”即将在4月30日与玩家见面,此前官方举办了更新内容预览会,详细介绍了本次版本的全新内容,让我们提前了解一下吧。

横版基地防御战斗游戏《余火守护者》现已登陆Steam
由Ratbit Games工作室开发的横版像素风基地防御战斗新游《余火守护者》已登陆Steam正式推出,并且支持中文。

为《巫师3》矮人角色卓尔坦·齐瓦配音的演员去世,终年81岁
曾为《巫师2》与《巫师3》里的卓尔坦·齐瓦(Zoltan Chivay)配音的苏格兰演员亚历山大·莫顿(Alexander Morton)离世,终年81岁。

闭门体验活动落下帷幕,《彩虹六号:攻势》国服首测六月战火燃起
近日,《彩虹六号:攻势》(下称“彩六国服”)在上海顺利举办了一场名为“入职国服48小时”的闭门体验活动。该活动围绕“用心、务实、透明”的核心品牌理念展开,全面呈现了团队在技术优化、本地化适配等领域的工作成果,并正式宣布:彩六国服计划于今年6月启动首次删档测试。









