发布时间:2025-07-29 15:07:04
7月28日晚,阿里带来惊喜,开源电影级视频生成模型通义万相Wan2.2,并全面接入通义APP。现在,用户仅需在通义APP里输入文本或图片,就能借助该模型首创的美学控制系统,轻松生成1080P高清且具电影质感的视频。目前单次可生成5秒视频,后续还会延长时长,视频创作将更高效,创作爱好者们快来体验!

近日,阿里开源视频生成模型通义万相Wan2.2,包括文生视频Wan2.2-T2V-A14B、图生视频Wan2.2-I2V-A14B和统一视频生成Wan2.2-IT2V-5B三款模型。
其中,文生视频模型和图生视频模型为业界使用MoE架构的视频生成模型,总参数量为27B,激活参数14B,在同参数规模下可节省约50%的计算资源消耗,在复杂运动生成、人物交互、美学表达等维度上取得了显著提升。5B版本统一视频生成模型同时支持文生视频和图生视频,可在消费级显卡部署,是目前24帧每秒、720P像素级的生成速度快的基础模型。

此外,阿里通义万相团队推出电影级美学控制系统,将光影、构图、色彩等要素编码成60多个直观的参数并装进生成模型。Wan2.2目前单次可生成5s的高清视频,可以随意组合60多个直观可控的参数。
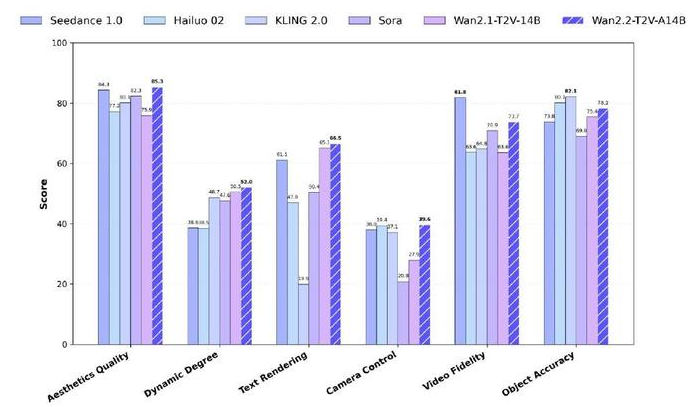
官方测试显示,通义万相Wan2.2在运动质量、画面质量等多项测试中超越了OpenAI Sora、快手Kling 2.0等领先的闭源商业模型。
业界使用MoE架构的视频生成模型有哪些技术创新点?5B版本又是如何实现消费级显卡可部署的?通过对话通义万相相关技术负责人,小编对此进行探讨解读。
目前,开发者可在GitHub、HuggingFace、魔搭社区下载模型和代码,企业可在阿里云百炼调用模型API,用户还可在通义万相官网和通义app直接体验。
推出MoE架构视频生成模型,5B版本消费级显卡可跑
根据官方介绍,通义万相Wan2.2的特色包括光影色彩及构图达到电影级,擅长生成复杂运动等,首先来看几个视频生成案例:
提示词1:Sidelit, soft light, high contrast, medium shot, centered composition, clean single subject frame, warm tones. A young man stands in a forest, his head gently lifted, with clear eyes. Sunlight filters through leaves, creating a golden halo around his hair. Dressed in a light-colored shirt, a breeze plays with his hair and collar as the light dances across his face with each movement. Background blurred, featuring distant dappled light and soft tree silhouettes.
(侧光照明,光线柔和,高对比度,中景镜头,居中构图,画面简洁且主体单一,色调温暖。一名年轻男子伫立在森林中,头部微微上扬,目光清澈。阳光透过树叶洒落,在他发间勾勒出一圈金色光晕。他身着浅色衬衫,微风拂动着他的发丝与衣领,每一个细微的动作都让光影在他脸上流转跳跃。背景虚化,隐约可见远处斑驳的光影和树木柔和的剪影。)
视频输出的gif截取:

背后,生成这些视频的生成模型有什么技术创新点?这要从视频生成模型在扩展规模(scale-up)时面临的挑战说起,主要原因在于视频生成需要处理的视频token长度远超过文本和图像,这导致计算资源消耗巨大,难以支撑大规模模型的训练与部署。
混合专家模型(MoE)架构作为一种应用于大型语言模型领域的模型扩展方式,通过选择专门的专家模型处理输入的不同部分,扩种模型容量却不增加额外的计算负载。
1、MoE架构的视频生成模型,高噪+低噪专家模型“搭档”
万相2.2模型将MoE架构实现到了视频生成扩散模型(Diffusion Model)中。考虑扩散模型的去噪过程存在阶段性差异,高噪声阶段关注生成视频的整体布局,低噪声阶段则更关注细节的完善,万相2.2模型根据去噪时间步进行了专家模型划分。
相比传统架构,通义万相Wan2.2 MoE在减少计算负载的同时有哪些关键效果提升?业界使用MoE架构,团队主要攻克了哪些难点?
通义万相团队相关负责人告诉记者,团队并不是将语言模型中的MoE直接套用到视频模型,而是用适配了视频生成扩散模型的MoE架构。该架构将整个去噪过程划分为高噪声和低噪声两个阶段:在高噪声阶段,模型的任务是生成视频大体的轮廓与时空布局;在低噪声阶段,模型主要是用来细化细节纹理和局部。每个阶段对应一个不同的专家模型,从而使每个专家专注特定的任务。
“我们的创新点是找到高阶噪声和低噪声阶段的划分点。不合理的划分会导致MoE架构的增益效果不足。我们引入了一个简单而有效的新指标——信噪比来进行指导,根据信噪比范围对高噪和低噪的时间T进行划分。通过这种MoE的架构,我们总参数量相比于2.1版本扩大了一倍,但训练和推理每阶段的激活值还是14B,所以整体的计算量和显存并没有显著增加,效果上是有效的提升了运动复杂运动和美学的生存能力。”这位负责人说。
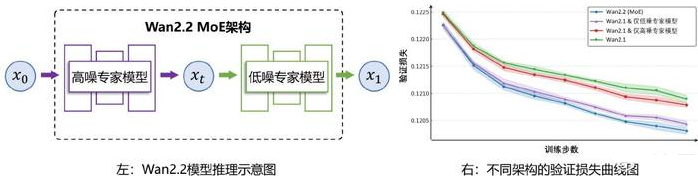
万相2.2的28B版本由高噪专家模型和低噪专家模型组成
2、数据扩容提高生成质量,支撑与美学精调
较上一代万相2.1模型,万相2.2模型的训练数据实现了显著扩充与升级,其中图像数据增加65.6%,视频数据增加83.2%。数据扩容提升了模型的泛化能力与创作多样性,使得模型在复杂场景、美学表达和运动生成方面表现更加出色。
模型还引入了专门的美学精调阶段,通过细粒度地训练,使得视频生成的美学属性能够与用户给定的Prompt(提示词)相对应。
万相2.2模型在训练过程中融合了电影工业标准的光影塑造、镜头构图法则和色彩心理学体系,将专业电影导演的美学属性进行了分类,并细致整理成美学提示词。
因此,万相2.2模型能够根据用户的美学提示词准确理解并响应用户的美学需求。训练后期,模型还通过强化学习(RL)技术进行进一步的微调,有效地对齐人类审美偏好。
3、高压缩比视频生成,5B模型可部署消费级显卡
为了更高效地部署视频生成模型,万相2.2探索了一种模型体积更小、信息下降率更高的技术路径。
通义万相Wan2.2开源5B版本消费级显卡可部署,该设计如何平衡压缩率与重建质量?
通义万相团队相关负责人告诉记者,为了兼顾性能与部署的便捷性,wan 2.2版本开发了一个5B小参数版。这一版本比2.1版本的14B模型小了一半多。同时团队采用了自研高压缩比VAE结构,整体实现了在特征空间上16×16的高压缩率,是2.1版本压缩率(8×8)的四倍,从而显著降低了显存占用。
为了解决高压缩比带来的问题,团队在这个VAE的训练中引入了非对称的编码结构以及残差采样机制;同时其还增加了这个隐空间的维度,把原来的2.1版本的16位增加到了48位。这样使模型在更大的压缩率下保持了良好的重建质量。
此次开源的5B版本采用了高压缩比VAE结构,在视频生成的特征空间实现了视频高度(H)、宽度(W)与时间(T)维度上32×32×4的压缩比,有效减少了显存占用。5B版本可在消费级显卡上快速部署,仅需xx显存即可在xx秒内生成5秒720p视频。此外,5B版本实现了文本生成视频和图像生成视频的混合训练,单一模型可满足两大核心任务需求。
此次开源中,万相2.2也同步公开了全新的高压缩比VAE结构,通过引入残差采样结构和非对称编解码框架,在更高的信息压缩率下依然保持了出色的重建质量。
结语:突破视频模型规模瓶颈,推动AI视频生成专业化演进
Wan2.2首创MoE架构视频生成模型,为突破视频模型规模瓶颈提供了新路径;5B版本大幅降低高质量视频生成门槛,加速生成式AI工具普及。
“电影级美学控制”将专业影视标准体系化融入AI,有望推动AI视频生成工具向更加专业化的方向发展,助广告、影视等行业高效产出专业内容;其复杂运动与物理还原能力的提升,显著增强了生成视频的真实感,为教育、仿真等多领域应用奠定基础。

火影忍者木叶高手前期怎么组队 火影忍者木叶高手前期配队技巧
火影忍者木叶高手前期怎么组队,前期组队至关重要,合理的阵容能助你轻松推图、快速积累资源。游戏里忍者品级与属性各异,搭配讲究策略。是优先选取强力的SSS级忍者,还是用SS级忍者过渡?如何平衡输出、防御与辅助?接下来将为你详细介绍前期组队方法与配队技巧,让你在木叶的冒险之旅事半功倍。

明末渊虚之羽云顶城地下监牢隐藏宝箱获取方法
《明末渊虚之羽》的云顶城地下监牢隐藏着一个神秘宝箱,其内含物对角色成长意义重大。然而,获取该宝箱的路径极为隐蔽,稍有疏忽便会错失良机。想知晓如何才能顺利拿到这个隐藏宝箱,让角色获得强力成长资源吗?接下来就为大家详细介绍云顶城地下监牢隐藏宝箱的获取方法,不妨看下进行参考 。

穿越火线灵音都市地图怎么玩 灵音都市地图玩法攻略
踏入《穿越火线》灵音都市地图,一场人类与幽灵的激烈较量即刻上演。这张以废弃都市为背景的地图,风格独特,建筑融合古风与现代元素。人类玩家身负护送车队抵达指定营地的重任,途中幽灵会从建筑内不断涌出攻击车队。究竟该如何在复杂地形中巧妙走位、合理选点防守?又怎样与队友配合,成功抵御幽灵的攻势?下面小编为大家揭开灵音都市地图的玩法奥秘,感兴趣可以看看。

《无畏契约:源能行动》约亚海悬城玩法详细介绍
《无畏契约:源能行动》中的约亚海悬城,也就是大家熟知的“义境空岛”,采用独特的三区域划分,为玩家带来丰富的战术体验。在这里,你将从南北两侧出生点出发,与队友并肩作战,争夺部署区控制权。A区、中区和B区各有特点,通道门的开关机制更增添变数。想知道如何在这张地图上大展身手吗?小编为大家详细介绍约亚海悬城玩法。

2025年古今2风起蓬莱公测最新兑换码大全
《古今2风起蓬莱》已经开启公测啦!为了让各位玩家能在游戏中快人一步,官方精心准备了超多福利,其中兑换码就是重要的一环。通过这些兑换码,大家可领取到丰富的资源,助力冒险。想知道都有哪些兑换码吗?马上为你揭晓2025年公测最新兑换码大全。


